Name Matching
Most filters and operations that work with names or other text data support advanced name matching. This section describes how this matching works.
Anatomy
Depending on the context, whether it is a filter or an operation, you may see a different layout of matching options. However, the underlying matching algorithm and options work the same way.

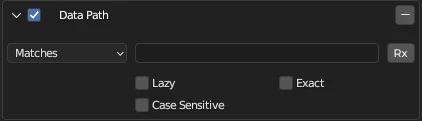
Default Matching
By default, matching is case-insensitive fragment matching:
- Case insensitive means that the uppercase and lowercase letters are treated as equivalent.
- Fragment means that the name needs to contain one or more characters of all text fragments (a text fragment is one or more characters separated by one or more space).
E.g.: If you enter cu ma, it will match all names that contain these two fragments. E.g.: UVMap Cube, Gamma Acuity, Cumarin, Macula, etc. It will not match names that contain only one fragment, e.g.: Cute, Man will not be matched.
This behavior can be modified by enabling match options such as:
Matching Options
Lazy
Match the name if it contains at least one of the entered fragments. E.g.: if you enter cu ma, it will match the names Cute, Man, UV Map Cube etc.
Case Sensitive
Treat uppercase and lowercase letters as distinct.
Exact
Strictly match the names to the entered query. E.g.: if you enter UVMap Cube, it will only match UVMap Cube. It will not match UV Map Cube (notice that the UV and Map words are separated by a space here), or UVMap Cube.001.
Regular Expression
Use regular expressions to match text. A great place to learn it is at Regular-Expression.info
PACKED Data Manager uses Python's regular expression engine. What regular expression features are available may depend on the version of Blender you are using, because different versions of Blender may come with different version of Python interpreter.
To see what Python version Blender is using open the Interactive console editor window (Shift + F4 ). Then type:
import sys- Hit Enter
sys.version_info- Hit Enter
You'll get the information that contains the Python version:
`sys.version_info(major=3, minor=10, micro=11, releaselevel='final', serial=0)`Here, the Python version is 3.10.11.
If a regular expression feature requires a Python version greater than the one in this result, it may not work.